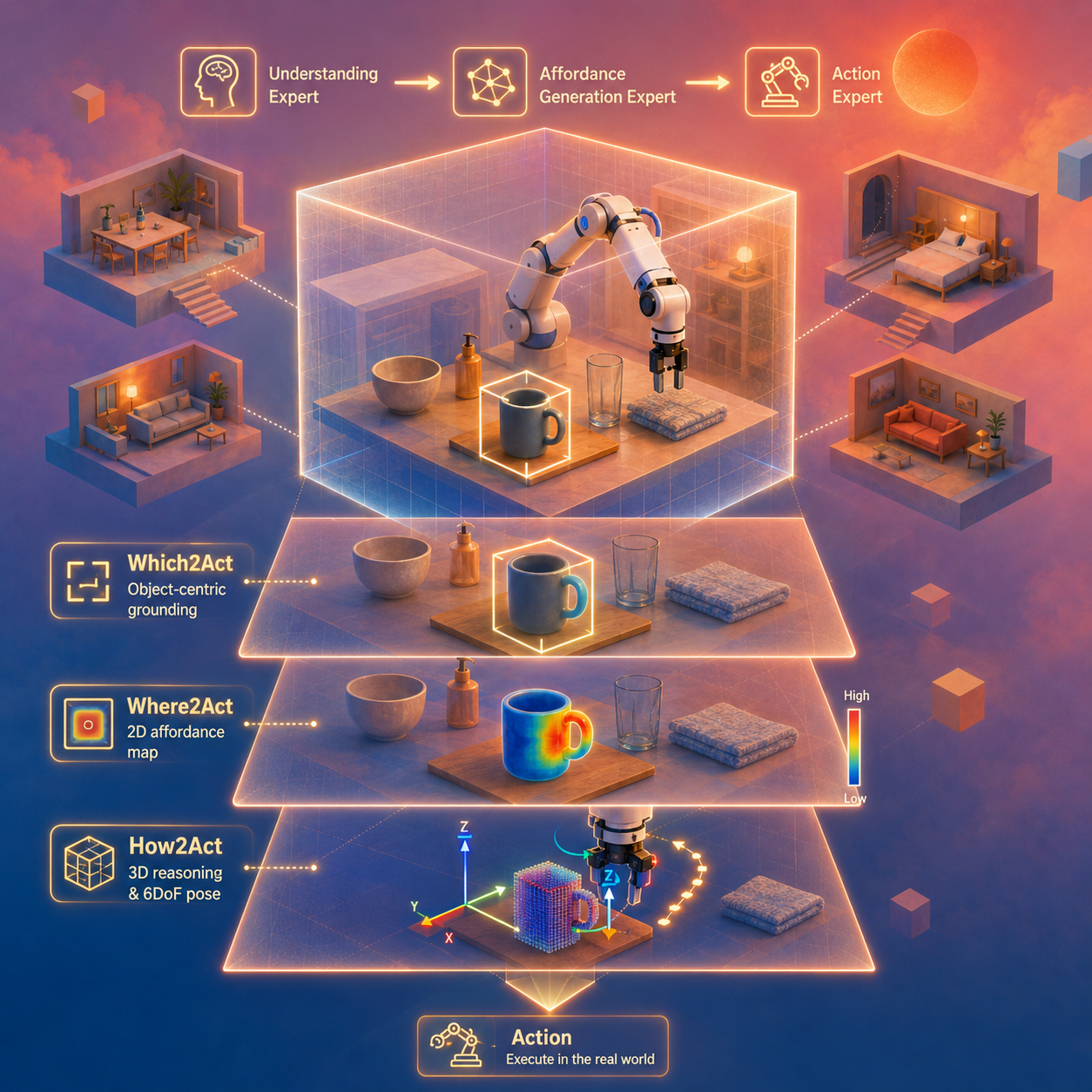
Empowering Action Generation through Affordance-Aware Understanding
Affordance as a Bridge: We introduce structured affordance forecasting as a task-oriented intermediate representation that connects vision, language, and action.
Which2Act · Where2Act · How2Act: Object-centric grounding, 2D interaction localization, and 3D geometric reasoning as complementary manipulation priors.
MoT + Three-Stage Curriculum: Specialized Understanding, Affordance Generation, and Action experts trained with a progressive data curriculum and an automated affordance-annotation pipeline.
Strong & Sample-Efficient: 95.8% on LIBERO, 4.33 avg. length on CALVIN ABC→D, 88.3% on real-world tasks — breaking the π0 ceiling with only 40% of the fine-tuning data.
1Peking University2HKUST (Guangzhou)3CUHK4Knowin AI
†Equal contribution *Corresponding authors
Overview
Figure 1: AffordanceVLA Overview.(Bottom-left) AffordanceVLA employs three specialized experts (Understanding, Affordance Generation, and Action), leveraging structured affordance forecasting (Which2Act, Where2Act, and How2Act) as intermediate representations to bridge perception and action. (Top) A three-stage training strategy with a progressive data curriculum (Bottom-right) enables AffordanceVLA to achieve strong performance across both simulation and real-world evaluations.
Vision-Language-Action (VLA) models leverage the rich world knowledge of pretrained VLMs to enable instruction-following robotic manipulation. However, the core of VLM pre-training is aligning vision and language in a semantic space, whereas robotic actions live in the 3D physical space — a structural mismatch that makes a direct mapping hard to learn and prone to representation collapse. We propose AffordanceVLA, which introduces structured affordance forecasting as a task-oriented intermediate representation. We progressively model manipulation priors through three complementary components: Which2Act (object-centric grounding via visual-latent prediction), Where2Act (2D interaction localization via affordance maps), and How2Act (3D geometric reasoning). Integrated into a Mixture-of-Transformer (MoT) architecture and trained with a three-stage progressive curriculum — backed by an automated pipeline that synthesizes 100K+ affordance labels — AffordanceVLA delivers strong, sample-efficient performance across simulation and real-world manipulation.
MotivationWithout innovating the model paradigm, blindly scaling up data fails to maximize the intrinsic power within the datasets, and relying solely on scaling is insufficient to resolve the fundamental spatial gap.
Key IdeaAffordances serve as a perfect bridge, seamlessly coupling spatial grounding in vision, semantic conditioning in language, and execution guidance in action.
Click any icon to jump to the corresponding section.
Method
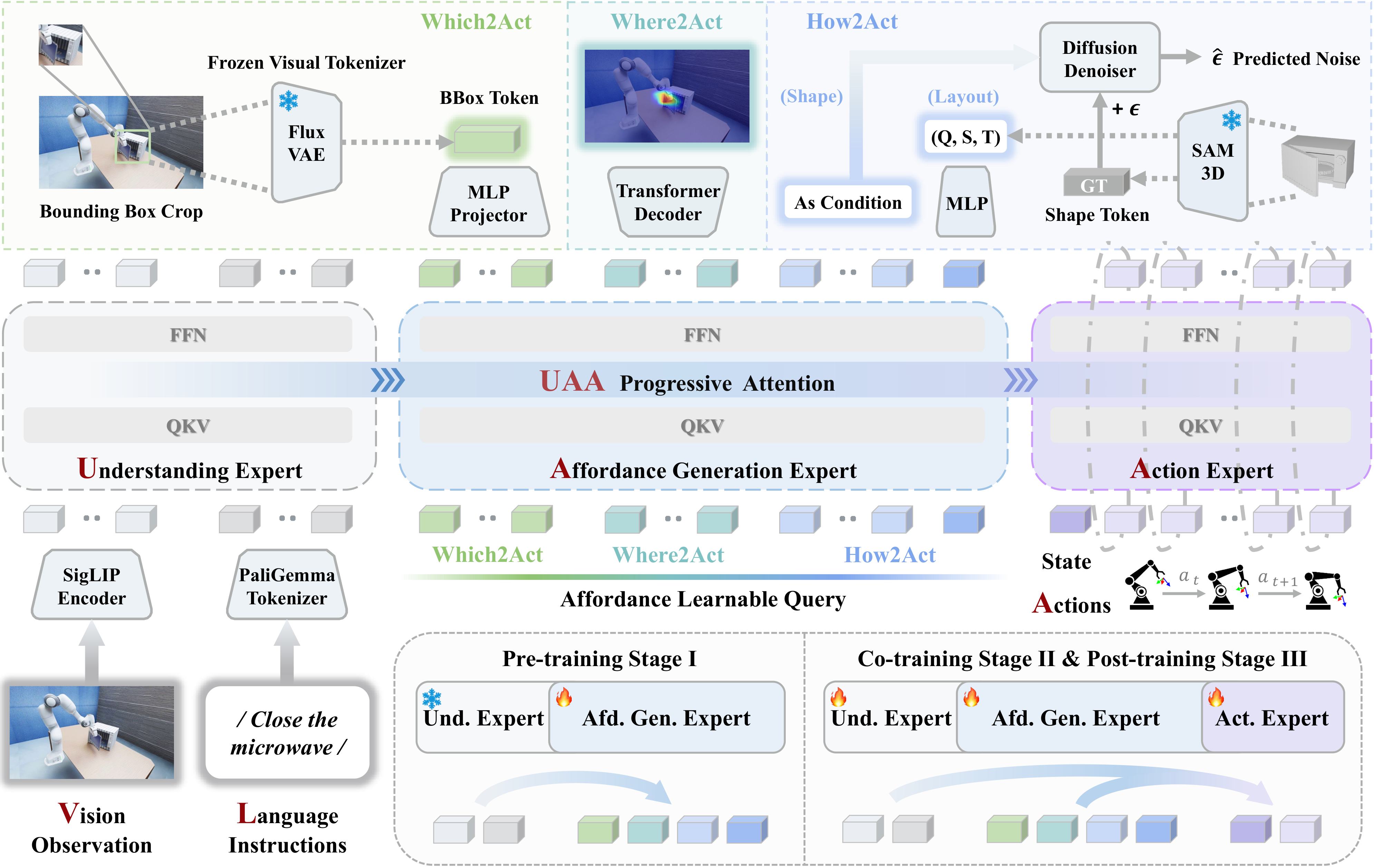
Previous works bridge perception and action via dense video prediction or visual foresight, but such signals are redundant and slow, while purely perceptive representations remain action-agnostic. Much like how humans naturally perceive a mug's handle as an invitation to grasp, affordances — manipulation priors that explicitly indicate which object to manipulate, as well as where and how to interact — serve as a perfect bridge by seamlessly coupling spatial grounding in vision, semantic conditioning in language, and execution guidance in action. AffordanceVLA unifies perception, prediction, and action by leveraging structured affordance forecasting as intermediate supervision within a Mixture-of-Transformer (MoT) architecture.
Figure 2: Pipeline.
The framework employs a MoT architecture comprising three specialized experts — Understanding (\(\mathcal{M}_{und}\)), Affordance Generation (\(\mathcal{M}_{gen}\)), and Action (\(\mathcal{M}_{act}\)) — coordinated via a unidirectional Understanding–Affordance–Action (UAA) progressive attention mechanism. Given an RGB observation \(O_t\) and instruction \(l\), \(\mathcal{M}_{und}\) extracts fused semantics \(h_t^{und}\). \(\mathcal{M}_{gen}\) then decodes \(h_t^{und}\) into structured affordance tokens \(\hat{A}_{t}\) (Which2Act, Where2Act, How2Act) as intermediate priors. Finally, \(\mathcal{M}_{act}\) synthesizes control actions \(\hat{a}_{t:t+k}\) conditioned on both \(h_t^{und}\) and \(\hat{A}_{t}\).
Three specialized experts. The Understanding Expert (\(\mathcal{M}_{und}\)) establishes a fine-grained alignment between visual perception and linguistic intent by leveraging pre-trained VLM priors, fusing the observation \(O_t\), instruction \(l\), and proprioceptive state \(s_t\) into an instruction-aware multimodal representation \(h_t^{und}\). The Affordance Generation Expert (\(\mathcal{M}_{gen}\)) acts as a visual planner, predicting a structured representation \(\hat{A}_{t}\) that anchors high-level semantics into actionable geometric cues. The Action Expert (\(\mathcal{M}_{act}\)) decodes these unified representations into smooth, temporally coherent action chunks — relieved from heavy visual reasoning, it focuses entirely on precise physical execution.
UAA progressive attention. To coordinate the experts, AffordanceVLA applies bidirectional intra-expert attention for thorough contextual fusion, while enforcing strict causal inter-expert attention across modules. The Affordance Generation Expert queries features exclusively from the Understanding Expert, while the Action Expert attends to the outputs of both preceding experts. This unidirectional flow prevents action information from leaking into the prediction stage, preserving the purity of affordance features and enhancing generalization.
Structured Affordance Knowledge
Rather than predicting monolithic global features, the Affordance Generation Expert disentangles learnable affordance queries into three parallel sub-modules that concurrently decode manipulation priors from coarse to fine and from 2D to 3D. Bidirectional attention jointly refines their representations, yielding task-relevant priors that unify vision, language, and action.
InsightAffordance is a natural vision–language–action bridge — spatially grounded, semantically conditioned, and action-coupled — that anchors the VLM's semantics while directly serving action generation.
Which
Which2Act
Object-centric grounding. Crops the observation by the target bounding box and reconstructs a continuous visual latent \(z_q\) from a frozen encoder (e.g., Flux VAE), isolating the interacting entity while filtering background distractions.
Where
Where2Act
2D interaction localization. Unfolds 1D query tokens into a 2D affordance map via a lightweight Transformer decoder, pinpointing interactive regions and providing explicit contact-point guidance.
How
How2Act
3D geometric reasoning. Bifurcates into a diffusion-based 3D shape generation branch and a 10-DoF spatial layout regression branch (rotation, scale, translation), equipping the Action Expert with spatial priors and kinematic constraints.
Which2Act aligns intents with visual entities by reconstructing the target latent \(\hat{z}\) via a Mean-Squared-Error objective:
Where2Act aligns the predicted spatial logits \(\hat{y}\) with the ground-truth mask \(M\) using a pixel-wise Binary Cross-Entropy loss, where \(\sigma(\cdot)\) is the sigmoid function:
How2Act formulates 3D shape prediction as a conditional diffusion process and regresses the 10-DoF spatial layout with a component-wise Smooth-L1 loss:
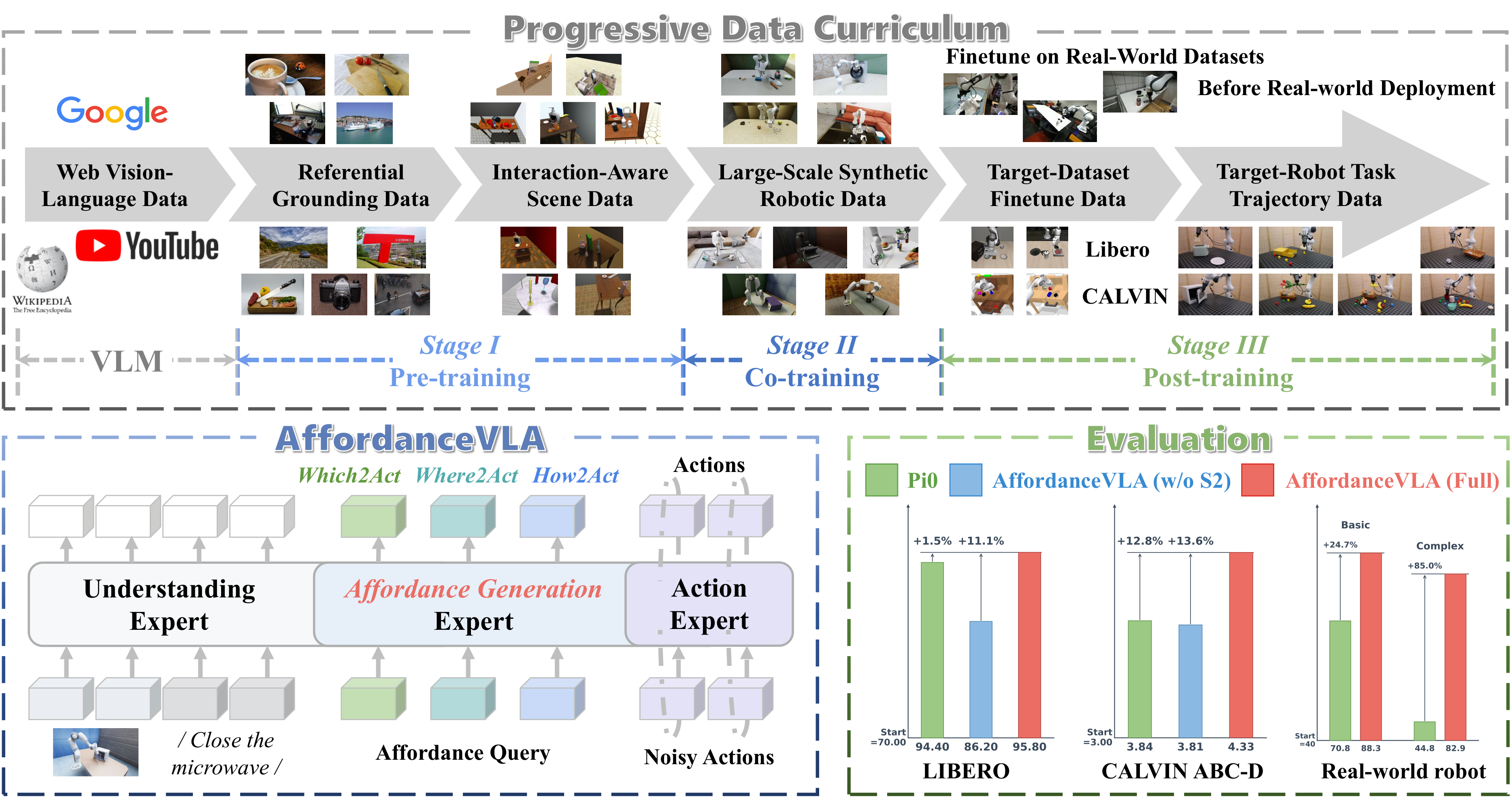
A three-stage curriculum transitions the model from broad visual–linguistic grounding to affordance-centric reasoning and finally to domain-specific embodied control:
Stage I — General Affordance Grounding Pre-training. Only the Affordance Generation Expert, learnable queries, and decoders are optimized (Vision Encoder, Understanding and Action Experts frozen) on referential grounding (AGD20K, RefSpatial) and interaction-aware scene data (PRISM), supervised by \(\mathcal{L}_{\text{Stage1}} = \lambda_{\text{which}}\mathcal{L}_{\text{which}} + \lambda_{\text{where}}\mathcal{L}_{\text{where}} + \lambda_{\text{shape}}\mathcal{L}_{\text{shape}} + \lambda_{\text{layout}}\mathcal{L}_{\text{layout}}\).
Stage II — Affordance-Augmented Robotic Co-Training. The Understanding and Action Experts are unfrozen for end-to-end alignment on large-scale synthetic robotic data (e.g., InternData-A1), with the joint objective \(\mathcal{L}_{\text{Stage2}} = \lambda_{\text{act}}\mathcal{L}_{\text{act}} + \lambda_{\text{afd}}\mathcal{L}_{\text{afd}}\).
Stage III — Target Task Post-Training. The generalized policy is adapted to specific downstream environments (LIBERO, CALVIN), deeply aligning semantics and affordance reasoning with target visual distributions and kinematic constraints.
Automated affordance-annotation pipeline. To overcome the scarcity of dense affordance labels, we extract keyframes from action sequences; a text LLM (Claude Opus 4.5) decomposes the global instruction into per-keyframe sub-instructions, and a VLM (Qwen3-VL) converts each keyframe into a detection category and a spatial affordance query. These guide a fine-tuned RexOmni (via PRISM), integrated with SAM and SAM-3D, to yield over 100,000 dense affordance annotations.
Design PhilosophyRich annotations should encode not just what to do but how to do it; structured affordance supervision preserves the backbone's vision–language ability instead of eroding it under the action loss (cf. π0.5/π0.7).
Real-World Demonstrations
AffordanceVLA is deployed on a real robot across three task families. The overlaid Where2Act affordance heatmaps reveal how the model grounds concise language instructions into precise interaction regions before acting.
Basic Tasks
Picking diverse objects across colors, shapes, and semantic categories — average success rate 88.3%.
Execution
Pick Up the Red Cup
Red Cup
Blue Cup
Banana
Duck
Bear
Flower
Complex Tasks — Instruction Sensitivity
Identical scene, different instruction. The Where2Act heatmap (right) shows where the model decides to act — disambiguating the command before execution (left).
Execution
Where2Act Affordance
Drawer — “Close the drawer”
Drawer: Close
Drawer: Pick
Toaster: Pick
Toaster: Toast
Long-Horizon & Robustness
Continuously clearing all rubbish from the table by re-evaluating the scene each step — and staying robust under human interference.
Long-Horizon
Pick All the Rubbish
Human Interference
Pick All the Rubbish — under Human Interference
Experiments
We evaluate AffordanceVLA on the LIBERO and CALVIN ABC→D simulation benchmarks as well as real-world tasks. We report two variants: AffordanceVLA (w/o stage II), which skips the affordance-augmented robotic co-training, and AffordanceVLA (full), trained with the complete three-stage strategy.
LIBERO Benchmark
Our full model attains a strong average of 95.8% — the highest among the methods compared here and competitive with the best recent VLAs. Strikingly, even without Stage II, AffordanceVLA (w/o stage II) already reaches 86.2%, showing that the decoupled MoT design isolates task-relevant semantics from raw control signals and curbs representation collapse (Q2). The margin narrows only on LIBERO-Long, where extremely long-horizon tasks would further benefit from explicit memory.
Method
Spatial
Object
Goal
Long
Average
OpenVLA
84.7
88.4
79.2
53.7
76.5
SpatialVLA
88.2
89.9
78.6
55.5
78.1
CoT-VLA
87.5
91.6
87.6
69.0
83.9
ThinkAct
88.3
91.4
87.1
70.9
84.4
π0
98.0
96.8
94.4
88.4
94.4
GR00T-N1
94.4
97.6
93.0
90.6
93.9
F1-VLA
98.2
97.8
95.4
91.3
95.7
AffordanceVLA (w/o stage II)
88.5
91.7
91.3
73.3
86.2
AffordanceVLA (full)
98.6
98.4
96.2
89.8
95.8
Table 1: Success rates (%) on the LIBERO benchmark over 50 rollouts. Best results in bold.
CALVIN ABC→D Benchmark
On this zero-shot OOD protocol (train on A/B/C, test on the visually novel Env D), AffordanceVLA (full) reaches a strong average length of 4.33, completing all 5 consecutive tasks in 75.9% of rollouts — competitive among recent VLAs (Q1). By forcing the model to focus on task-critical entities, interaction regions, and spatial layouts, structured affordance prediction makes the perception–action mapping resilient to novel visual disturbances. The substantial jump from the w/o-stage-II variant (3.81) underscores the necessity of Stage II co-training for OOD generalization (Q3).
Method
1/5
2/5
3/5
4/5
5/5
Avg. Len
RoboFlamingo
82.4
61.9
46.6
33.1
23.5
2.48
SuSIE
87.0
69.0
49.0
38.0
26.0
2.69
GR-1
85.4
71.2
59.6
49.7
40.1
3.06
OpenVLA
91.3
77.8
62.0
52.1
43.5
3.27
CLOVER
96.0
83.5
70.8
57.5
45.4
3.53
UniVLA
95.5
85.8
75.4
66.9
56.5
3.80
π0
93.8
85.0
76.7
68.6
60.1
3.84
Seer
94.4
87.2
79.9
72.2
64.3
3.98
VPP
95.3
88.2
80.3
72.9
64.5
4.01
Seer-Large
96.3
91.6
86.1
80.3
74.0
4.28
AffordanceVLA (w/o stage II)
93.4
84.7
75.4
68.1
58.9
3.81
AffordanceVLA (full)
96.8
92.0
87.5
80.8
75.9
4.33
Table 2: Success rates (%) for completing 1–5 consecutive tasks on CALVIN ABC→D over 1000 rollouts, with average completed length (Avg. Len).
Real-World Experiments
Across Basic Tasks, AffordanceVLA reaches an average success rate of 88.3%, consistently outperforming the π0 baseline over diverse objects, colors, and shapes. On Complex Tasks with severe visual aliasing (identical observations, distinct instructions), it unambiguously grounds concise intents into localized affordance heatmaps — e.g., 86.7% / 100.0% on Drawer (pick) / (close) versus π0's 46.7% / 40.0% — and sustains long-horizon execution on Pick all the rubbish.
Method
Close
Pick up (Color)
Pick up (Shape)
Pick up
Average
microwave
safe
red
green
duck
banana
flower
bear
π0
86.7
86.7
80.0
80.0
26.7
73.3
53.3
80.0
70.8
AffordanceVLA
93.3
100.0
86.7
80.0
86.7
86.7
80.0
93.3
88.3
Table 3: Average success ratio (%) on Basic real-world tasks (15 trials per task).
Method
Drawer
Toaster
Pick all the rubbish
Average
pick
close
pick
toast
1st ↑
2nd ↑
3rd ↑
Empty ↓
π0
46.7
40.0
46.7
26.7
93.3
53.3
6.7
33
44.8
AffordanceVLA
86.7
100.0
80.0
86.7
100.0
80.0
46.7
11
82.9
Table 4: Average success ratio (%) on Complex real-world tasks. For Pick all the rubbish, we report 1st/2nd/3rd continuous success and total Empty Picks (lower is better).
Figure 3: Real-World Experiment Visualizations.Top: qualitative results for Basic tasks. Bottom-left: visualizations of the Where2Act token for the Drawer and Toaster tasks. Right: sequential execution of the continuous Pick all the rubbish task.
Analysis
Where does the gain come from? A natural concern is whether the improvement stems from high-quality data, added supervision density, or the structured representation itself. We design three controls that each hold one factor fixed:
Data-Only Control (No-Afd). A plain π0 architecture on the same Stage II data, without the affordance objective, improves only marginally (LIBERO 92.4%, CALVIN 3.93 vs. π0's 3.84). The gain is not data volume per se.
Frozen-Representation Control (Frozen-Afd). Freezing the affordance expert after Stage I — treating affordance as a fixed external prior — triggers a severe collapse (67.1% / 2.83). Affordance must be co-optimized with the control policy.
Same-Density Control (Block-wise Tokens). Keeping the losses and data — hence the total supervision density — identical, and only forbidding the three heads from cross-attending, drops results to 90.3% / 3.89. This rules out the “multi-task density” explanation: the structured, jointly-refined representation is what drives the gain.
Together these directly answer Q2: it is the decoupled, jointly-optimized MoT design — not merely more data nor an off-the-shelf affordance module — that prevents collapse and unlocks the gains.
Method
LIBERO (Success Rate %)
CALVIN ABC→D
Spatial
Object
Goal
Long
Avg.
1/5
3/5
5/5
Avg. Len
Architecture Design & Training Strategy
No-Afd (Pi0 Arch)
96.0
95.4
92.4
85.8
92.4
94.5
78.0
62.8
3.93
Frozen-Afd
68.0
71.1
66.4
62.9
67.1
85.3
55.9
26.3
2.83
AffordanceVLA w/o stage II
88.5
91.7
91.3
73.3
86.2
93.4
75.4
58.9
3.81
Affordance Representation
w/o Which2Act
97.5
97.6
95.0
88.1
94.6
96.7
83.3
72.1
4.20
w/o Where2Act
95.5
96.0
93.4
88.0
93.2
96.2
81.9
69.8
4.13
w/o How2Act
96.1
96.5
93.9
88.2
93.7
95.0
79.4
65.9
4.01
Attention Mechanism for Affordance
Block-wise Tokens
92.4
92.9
89.8
86.0
90.3
94.1
77.1
61.7
3.89
AffordanceVLA (Full)
98.6
98.4
96.2
89.8
95.8
96.8
87.5
75.9
4.33
Table 5: Ablation study on LIBERO and CALVIN ABC→D. Best results in bold.
Structured representation (Q1). Removing any single head (Which/Where/How2Act) yields only a graceful degradation rather than a catastrophic collapse — evidence that the three sub-modules are not a brittle Which→Where→How pipeline, but are jointly refined under a shared instruction-aware representation and consumed together by the Action expert. Notably, How2Act's benefit is modest on simple tabletop two-finger settings yet becomes pronounced on complex real-world 6-DoF interactions, exactly where 3D shape and layout priors matter most.
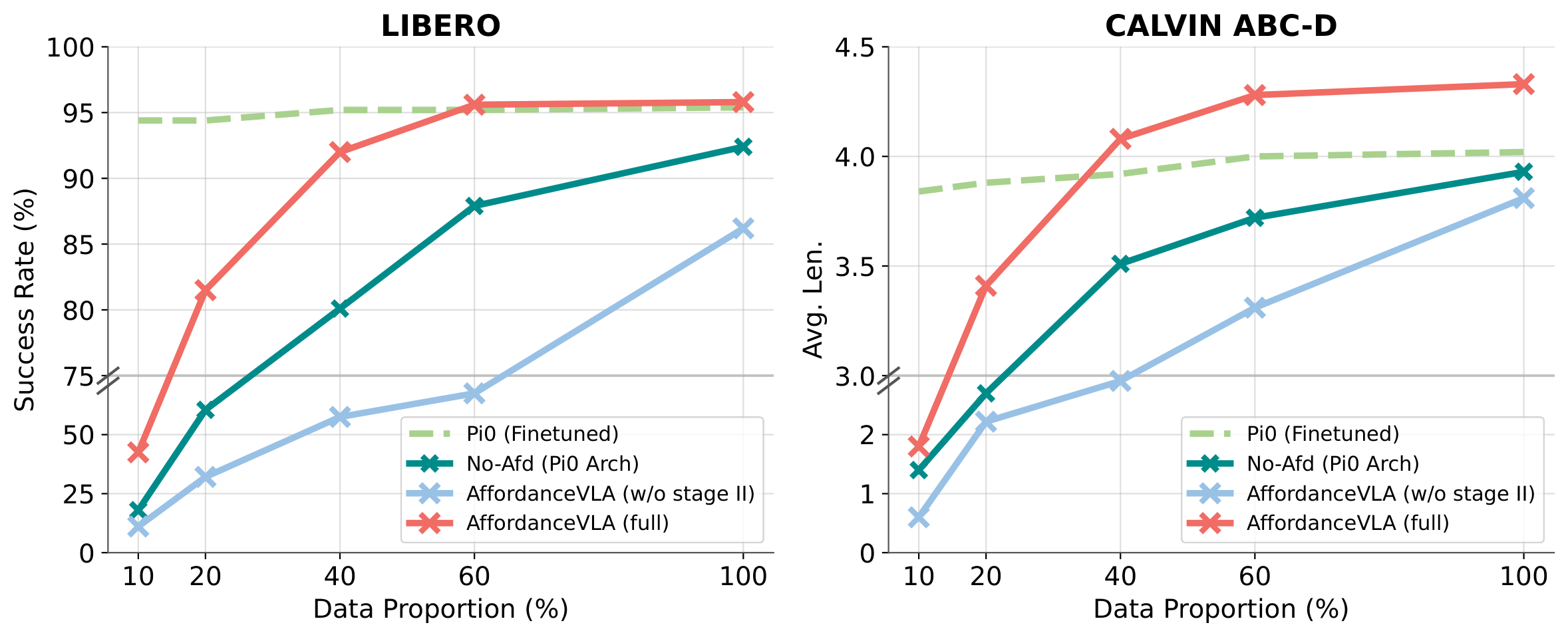
Data Efficiency
Scaling downstream fine-tuning data from 10% to 100%, the vanilla π0 starts strong (pre-trained weights) but quickly hits a rigid ceiling. AffordanceVLA instead surges: with only 40% of the data it already attains ~92% on LIBERO and an average length above 4.0 on CALVIN, shattering the ceiling of the fully fine-tuned π0. Because the affordance representation decomposes the perception–action mapping into interpretable sub-problems, each sample supervises not only the action but also object grounding, spatial localization, and 3D reasoning — effectively multiplying the learning signal per sample.
Figure 4: Data Efficiency.
Across both LIBERO (left) and CALVIN ABC→D (right), AffordanceVLA (full) recovers from the initial distribution shift of specialized pre-training and surpasses the fully fine-tuned π0 with far fewer downstream samples, while the No-Afd and w/o-Stage-II ablations recover much more slowly.
FindingArchitecture unlocks data potential: π0 saturates while we break its ceiling at 40% data — architecture × representation × data are mutually amplifying.
Why Does Affordance Help?
A closer look at failure modes is revealing. In the Toaster task, π0 performs poorly (toast 26.7% vs. our 86.7%) and its bad cases concentrate at the button-pressing step: instead of extending to press the button, it often closes the gripper as if still doing a pick-and-place, largely disregarding the “press the button” instruction. Even after real-trajectory fine-tuning, π0 still suffers from weak instruction following — its behavior is driven by the dominant action prior rather than the language command. We offer an intuition for why affordance grounding alleviates this: in an action-only VLA, the low-level action loss is back-propagated directly into the VLM backbone and may gradually erode the instruction-following ability that pre-training endowed. Recent strong policies (π0.5, π0.7) implicitly mitigate this with train-only structured supervision; affordance plays a similar — arguably more natural — role, keeping its training signal close to the VLM's semantic space.
HypothesisWe conjecture that affordance acts as a structured semantic anchor: rather than letting the low-level action loss reshape the VLM directly, the affordance objective — being close to vision–language semantics — helps preserve the backbone's instruction-following ability, in spirit with the train-only intermediate cues adopted by recent strong VLAs.
Key takeaway. Structured affordance forecasting — jointly answering which, where, and how to act — is a more effective intermediate representation than dense visual foresight. Coupled with a decoupled MoT architecture and progressive training, it yields a precise, robust, and sample-efficient perception–action mapping.
Conclusion
We present AffordanceVLA to bridge the structural gap between the semantic space of Vision-Language Models and the 3D physical requirements of embodied control. Instead of relying on direct end-to-end mappings or redundant visual foresight, our framework adopts affordances as a task-oriented intermediate representation and decomposes affordance forecasting into Which2Act, Where2Act, and How2Act. With a Mixture-of-Transformer architecture and a progressive data curriculum, AffordanceVLA achieves strong, competitive performance on LIBERO, CALVIN, and real-world experiments, demonstrating strong generalization and robust reasoning. Future work will explore explicit temporal modeling as well as extensions to bimanual and deformable object manipulation.
Explore More Awesome Affordance
Want to discover more of the magic of affordance? Check out these awesome works:
@misc{yu2026affordancevlavisionlanguageactionmodelempowering,
title={AffordanceVLA: A Vision-Language-Action Model Empowering Action Generation through Affordance-Aware Understanding},
author={Qize Yu and Jiadi You and Yuran Wang and Jiaqi Liang and Bowen Ping and Yang Tian and Yue Chen and Minghong Cai and Zeying Gong and Ruihai Wu and Yinchuan Li and Junwei Liang and Yingcong Chen},
year={2026},
eprint={2606.06155},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2606.06155},
}